I am a computer science Ph.D. student at The University of Texas at Arlington (UTA). Currently, I am working in IDIR Lab under the supervision of Dr. Chengkai Li. I have interests in research areas related to Big Data and Data Science, including Database and Data Mining. I have published in prestigious venues such as VLDB, CIKM, ICDE and IEEE Transactions on Knowledge and Data Engineering (TKDE). My works have won several awards including Excellent Demonstration Award (VLDB 2014), President’s Award (ACES 2016, Graduate Poster) and Dissertation Fellowship. Before joining the Ph.D. program, I worked as a lecturer in Daffodil International University after completing B.Sc. from Bangladesh University of Engineering and Technology (BUET).

Starting from Fall 2016, I will join the computer science department of The University of Mississippi. Interested and self-motivated Ph.D. applicants are encouraged to contact. Research Assistant (RA) positions are available.

-
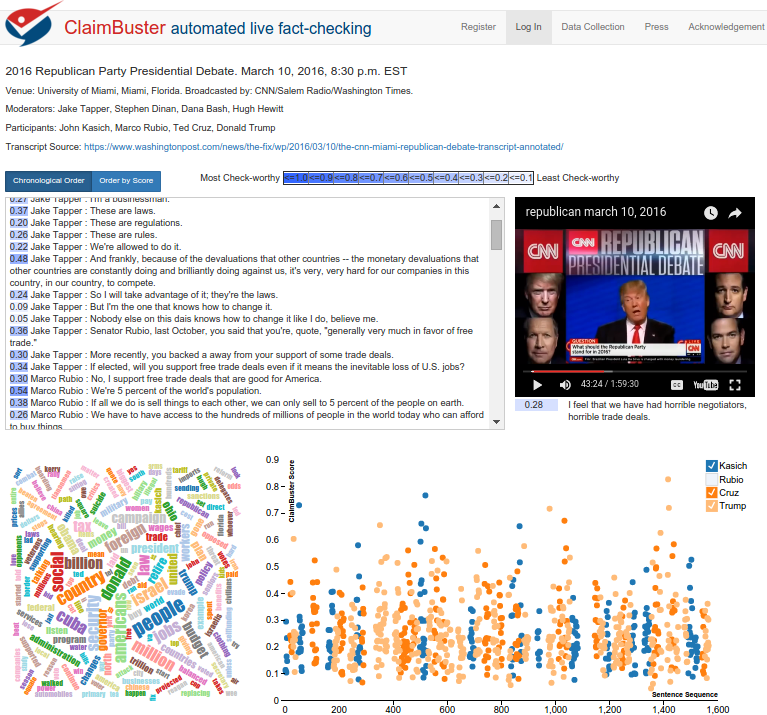
Automated Fact-checking: Politicians and media figures make claims about “facts” all the time. The new army of fact-checkers can often expose claims which are false, exaggerated or half-truths. Technology, social media and new forms of journalism have made it easier than ever to disseminate falsehoods and half-truths faster than the fact-checkers can expose them. This “gap” in time and availability limits the effectiveness of fact-checking. The goal of this project is to pursue towards a completely automatic fact-checking platform, investigate the technical challenges and propose potential solutions [C+J 2015]. We are building ClaimBuster [CIKM 2015], a platform to monitor live streams, websites, and social media to catch factual claims, detect matches with a curated repository of fact-checks, and deliver the matches instantly to viewers. Major components of the platform are- text mining, social media analysis and collaborative fact-checking. This project has received media attention from multiple news outlets, including the guardian, Austin American-Statesman, Poynter and New Scientist.
-
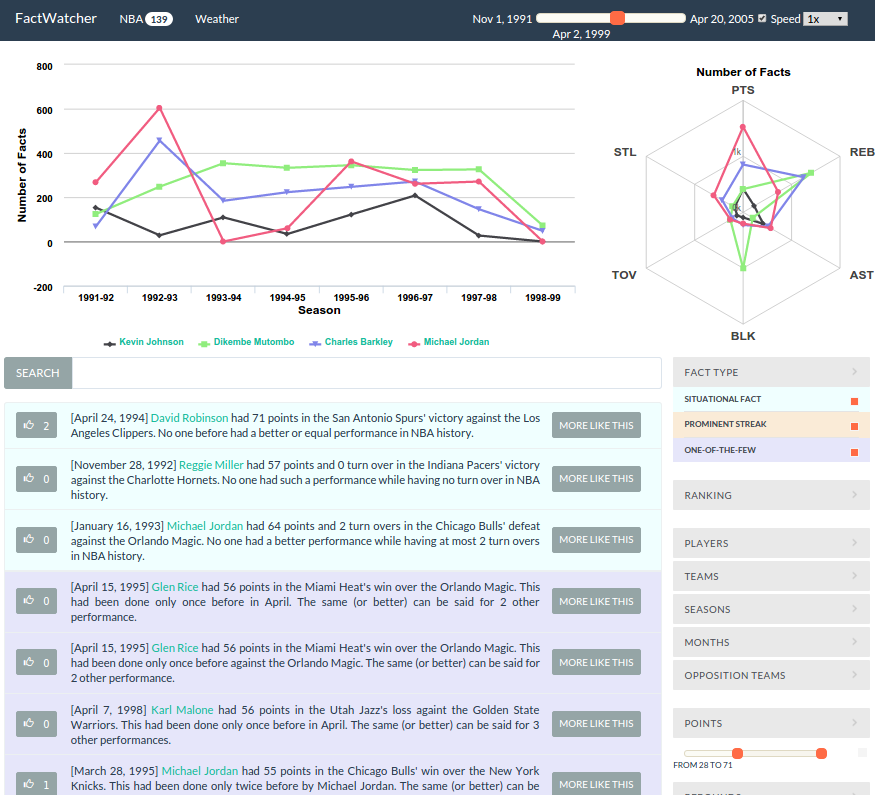
Significant Fact Monitoring: The goal of this project is to augment journalists identify data-backed, attention-seizing facts which serve as leads to news stories. Examples of such facts are- “This month the Chinese capital has experienced 10 days with a maximum temperature in around 35 degrees Celsius—the most for the month of July in a decade”, “Michael Jordan had 53 points in the Chicago Bulls' win over the Detroit Pistons. No one before had a better or equal performance in 1995-96 season”. Given an append-only database, upon the arrival of a new tuple, the challenge is to design algorithms which efficiently search for facts without exhaustively testing all possible ones [ICDE 2014, C+J 2014]. We developed FactWatcher [VLDB 2014], a system which finds story leads from ever-growing data and provides features including fact ranking, fact-to-statement translation, and keyword-based fact search. This system won an Excellent Demonstration Award in VLDB 2014.
-
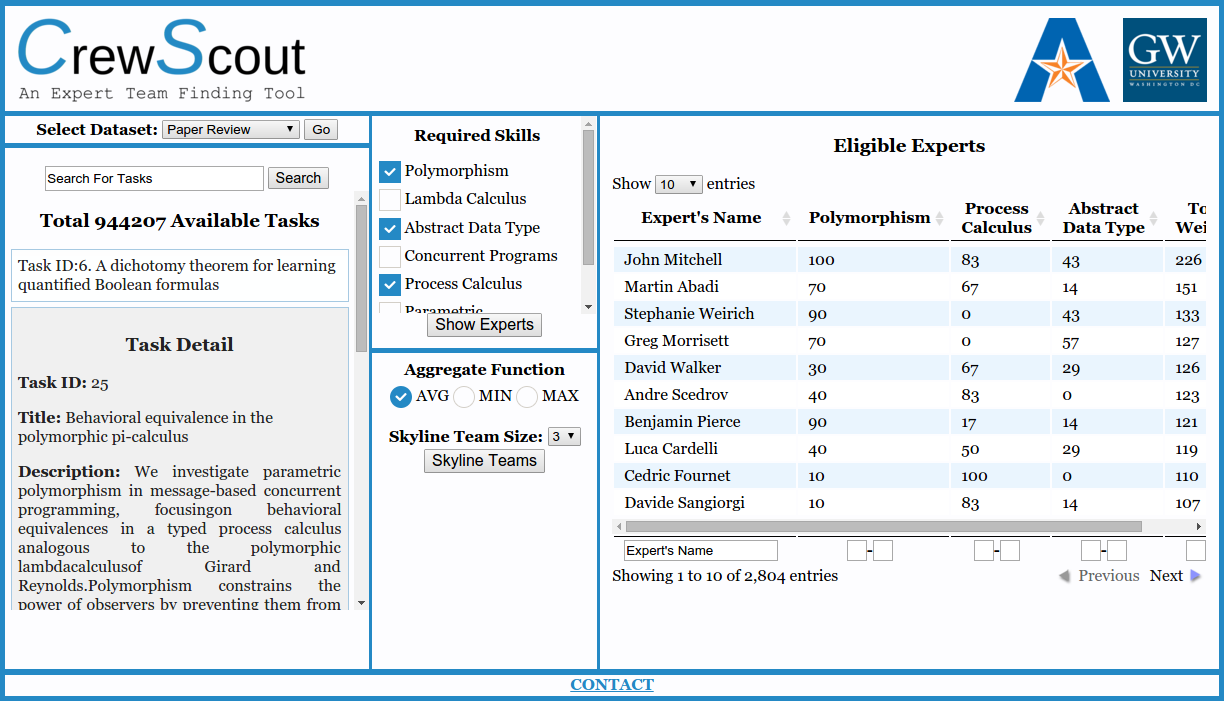
Skyline Group: Traditional Pareto frontier (skyline) computation is inadequate to answer queries which need to analyze not only individual points but also groups of points. To approach this gap, we proposed a novel concept “Skyline Group” [TKDE 2014, CIKM 2012] that represents groups which are not dominated by any other groups. We demonstrated its applications through a web-based system CrewScout [CIKM 2014] in question answering, expert team formation and paper reviewer selection. An attractive characteristic of a skyline team is that no other team of equal size can dominate it. In contrast, given a non-skyline team, there is always a better skyline team. This property distinguishes CrewScout from other team recommendation techniques.
-
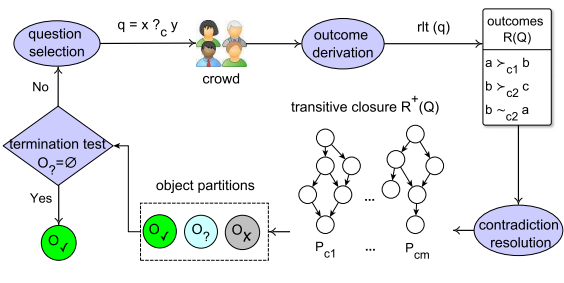
Crowdsourcing Pareto-optimal Objects: Finding Pareto-optimal objects through crowdsourcing has applications in public opinion collection, group decision making, and information exploration. Departing from prior studies on crowdsourcing skyline and ranking queries, it considers the case where objects do not have explicit attributes and preference relations on objects are strict partial orders. The partial orders are derived by aggregating crowdsourcers’ responses to pairwise comparison questions. The goal is to find all Pareto-optimal objects by the fewest possible questions [CIKM 2015].
| University of Mississippi | |
|---|---|
| Csci 581: Data Mining | FALL 2016 |
| University of Texas at Arlington | |
|---|---|
| CSE 4334/5334: Data Mining | FALL 2014 |
| CSE 6324: Advanced Topics in Software Engineering | SPRING 2014 |
| CSE 5311: Design and Analysis of Algorithms | FALL 2013, FALL 2011 |
| CSE 3330: Database Systems and File Structures | SPRING 2012, SUMMER 2011, SPRING 2011, FALL 2010 |
| CSE 1310: Introduction to Computers and Programming | SPRING 2011 |
| Daffodil International University |
|---|
| Computer Fundamentals, Numerical Methods, Instrumentation and Control, Electrical Circuit, Compiler, Simulation and Modeling, VLSI. |
| Mentor (University of Texas at Arlington) | |
|---|---|
| Current M.S. students | Vikas Sable, Siddhant Gawsane, Pratik Palashikar, Abu Ayub Ansari |
| Current B.S. students | Josue Caraballo |
| Graduated M.S. students | Fatma Dogan (December 2015), Minumol Joseph (December 2015) |
| Graduated B.S. students | Huadong Feng (May 2014) |
- Naeemul Hassan, Mark Tremayne, Fatma Arslan and Chengkai Li. Comparing Automated Factual Claim Detection Against Judgments of Journalism Organizations. In Proceedings of the 2016 Computation+Journalism Symposium, 5 pages, San Francisco, CA, USA, September 2016. [Paper]
- Naeemul Hassan, Chengkai Li, and Mark Tremayne. Detecting Check-worthy Factual Claims in Presidential Debates. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management (CIKM), pages 1835-1838, Melbourne, Australia, October 2015. DOI 10.1145/2806416.2806652. [Paper] [Poster]
- Abolfazl Asudeh, Gensheng Zhang, Naeemul Hassan, Chengkai Li, and Gergely Zaruba. Crowdsourcing Pareto-Optimal Object Finding by Pairwise Comparisons. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management (CIKM), pages 753-762, Melbourne, Australia, October 2015. DOI 10.1145/2806416.2806451. [Paper]
- Naeemul Hassan, Bill Adair, James Hamilton, Chengkai Li, Mark Tremayne, Jun Yang and Cong Yu. The Quest to Automate Fact-Checking. In Proceedings of the 2015 Computation+Journalism Symposium, 5 pages, New York City, USA, October 2015. [Paper]
- Naeemul Hassan, Huadong Feng, Ramesh Venkataraman, Gautam Das, Chengkai Li, and Nan Zhang. Anything You Can Do, I Can Do Better: Finding Expert Teams by CrewScout. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management (CIKM), pages 2030-2032, Shanghai, China, November 2014. DOI 10.1145/2661829.2661839. [Paper] [Poster] [Demo]
- Naeemul Hassan, Afroza Sultana, You Wu, Gensheng Zhang, Chengkai Li, Jun Yang, and Cong Yu. Data In, Fact Out: Automated Monitoring of Facts by FactWatcher. In Proceedings of the VLDB Endowment (PVLDB), pages 1557-1560, Hangzhou, China, September 2014. DOI 10.14778/2733004.2733029. Excellent demonstration award. [Paper] [Poster] [Demo]
- Brett Walenz, You (Will) Wu, Seokhyun (Alex) Song, Emre Sonmez, Eric Wu, Kevin Wu, Pankaj K. Agarwal, Jun Yang, Naeemul Hassan, Afroza Sultana, Gensheng Zhang, Chengkai Li, and Cong Yu. Finding, Monitoring, and Checking Claims Computationally Based on Structured Data. In Proceedings of the 2014 Computation+Journalism Symposium, 5 pages, New York City, USA, October 2014. [Paper] [Presentation]
- Nan Zhang, Chengkai Li, Naeemul Hassan, Sundaresan Rajasekaran, and Gautam Das. On Skyline Groups. IEEE Transactions on Knowledge and Data Engineering (TKDE), 26(4):942-956, April 2014. DOI 10.1109/TKDE.2013.119. [Paper]
- Afroza Sultana, Naeemul Hassan, Chengkai Li, Jun Yang, and Cong Yu. Incremental Discovery of Prominent Situational Facts. In Proceedings of the 30th International Conference on Data Engineering (ICDE), pages 112-123, Chicago, Illinois, April 2014. DOI 10.1109/ICDE.2014.6816644. [Paper] [Presentation]
- Chengkai Li, Nan Zhang, Naeemul Hassan, Sundaresan Rajasekaran, and Gautam Das. On Skyline Groups. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management (CIKM), pages 2119-2123, Maui, Hawaii, November 2012. DOI 10.1145/2396761.2398585. [Paper] [Presentation]
- Zamshed Iqbal Chowdhury, Masudul Haider Imtiaz, Muhammad Moinul Azam, Mst Sumi, Rumana Aktar, Md Rahman, Farzana Alam, Ishtiak Hussain and Naeemul Hassan. Design and Deployment of a Robust Remote River Level Sensor Network. IEEE Sensors Applications Symposium (SAS), pages 244-249, San Antonio, Texas, February 2011. DOI 10.1109/SAS.2011.5739776. [Paper]
- SM Rifat Ahsan, Mohammad Saiful Islam, Naeemul Hassan and Ashikur Rahman. Exploiting Packet Distribution for Tuning RTS Threshold in IEEE 802.11. IEEE 25th Biennial Symposium on Communications (QBSC), pages 369-372, Kingston, Ontario, Canada, May 2010. DOI 10.1109/BSC.2010.5472955. [Paper]
- SM Rifat Ahsan, Mohammad Saiful Islam, Naeemul Hassan and Ashikur Rahman. Packet Distribution Based Tuning of RTS Threshold in IEEE 802.11. IEEE Symposium on Computers and Communications (ISCC), pages 1-6, Riccione, Italy, June 2010. DOI 10.1109/ISCC.2010.5546703. [Paper]
- ClaimBuster: Detecting Check-worthy Factual Claims in Presidential Debates. Knight Foundation Demo Day, Miami, April 2016.
- ClaimBuster: a tool that can analyze transcripts from debates, TV interviews and legislative proceedings and instantly find factual claims to check. Tech & Check, Duke University, March 2016.
- Computational Journalism. CSE 5334- Data Mining, University of Texas at Arlington, February 2016.
- Towards Automated Fact-checking. University of Mississippi, March 2016.
- Data Science for Computational Journalism. The Dallas Morning News, Texas, April 2015.
- Skyline Queries. CSE 5334- Data Mining, University of Texas at Arlington, December 2012.
- Introduction to PHP. CSE 3330- Database, University of Texas at Arlington, April 2012.
- On Skyline Groups. CSE 5334- Data Mining, University of Texas at Arlington, April 2012.
- President’s Award (Graduate Poster Presentation). ACES 2016
- Ph.D. Dissertation Fellowship. University of Texas at Arlington. Spring 2016
- Graduate Fellowship. University of Texas at Arlington. Fall 2015, Spring 2016
- Outstanding Teaching Assistant Award. University of Texas at Arlington. Spring 2015
- CIKM 2015 Travel Grant
- Computation+Journalism Symposium 2015 Travel Grant
- Excellent Demonstration Award. VLDB 2014 (out of 115 submissions)
- STEM Fellowship. University of Texas at Arlington. Fall 2010 – Summer 2016
- Dean’s List Award. Bangladesh University of Engineering & Technology (BUET). 2007 – 2009
- Computer Science & Engineering Academic Merit Scholarship. BUET. 2007 – 2009
- University Engineering Scholarship. BUET. 2006 – 2009