Check Out Our Work!
GitHub
Dataset
Medium
Presentation
Slides
Presentation
Talk
Brief Overview
Knowledge Graphs (KGs) represent semantic information using triples. Knowledge Graph Completion (KGC) involves predicting missing relationships in KGs and enhancing their completeness. KG Link Prediction predicts missing elements in triples, and KG embedding models use machine learning to represent entities and relationships as continuous vectors. Access to large-scale KGs is vital for robust model development. Our papers focus on challenges posed by Freebase's data modeling features and introduce variants of the dataset, addressing gaps in understanding and offering the first publicly available full-scale Freebase dataset for KG link prediction evaluation.
Keywords
Knowledge graph completion · Link prediction · Knowledge graph embedding · Benchmark dataset
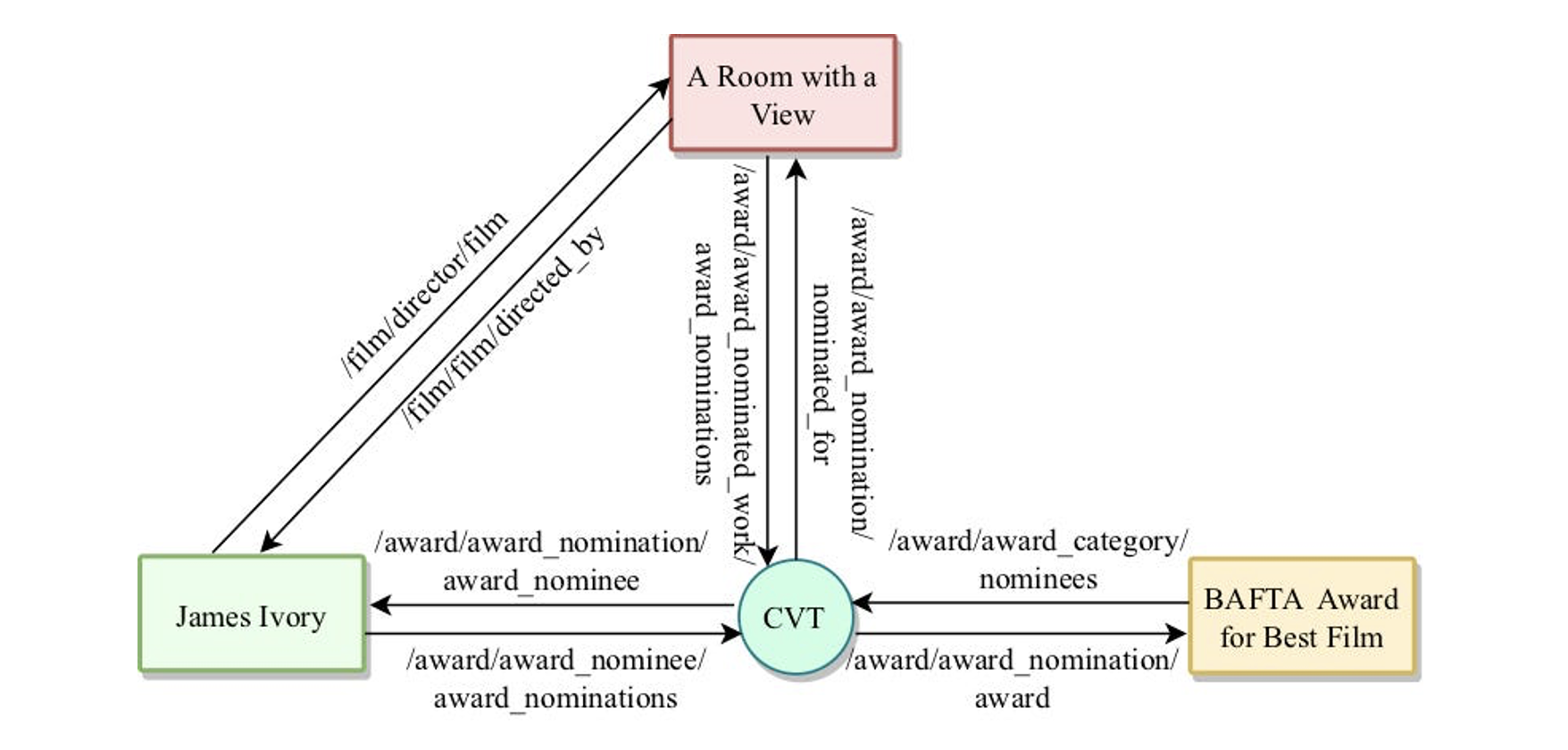
A small fragment of Freebase, with a mediator node
Background
-
Knowledge Graphs (KGs)
Knowledge graphs (KGs) represent semantic information as (subject s, predicate p, object o) triples, forming a graph where entities are nodes and connections are directed edges. They integrate diverse data across domains, powering applications in AI and machine learning. Widely used in industry, KGs are crucial for tasks like natural language processing, search, and recommender systems, making them vital assets for tech companies and governments.
-
Knowledge Graph Completion (KGC) and its importance
Knowledge Graph Completion (KGC) is a task in knowledge representation and machine learning. It involves predicting missing relationships or facts in a knowledge graph. The importance of KGC lies in its ability to enhance the completeness and accuracy of knowledge graphs. By predicting missing relationships, KGC contributes to filling gaps in the knowledge representation, making knowledge graphs more comprehensive and useful.
-
Knowledge Graph Link Prediction Task
KG Link Prediction is the task of predicting missing s in triple (?, p, o) or missing o in (s, p, ?). Commonly, KG link prediction models are trained on existing relationships in the knowledge graph and then applied to predict potential links that might exist but are not explicitly stated.
-
KG embedding models
KG embedding models are machine learning models designed to represent entities and relationships in a KG as continuous vector embeddings. These embeddings capture semantic relationships between entities and enable mathematical operations to be performed on them. Common approaches include TransE, TransR, and ComplEx, which aim to learn embeddings that preserve the structure and semantics of the KG. The vectors in KG embedding models are learned through optimization processes that minimize a specific score function. The score function measures the compatibility or likelihood of a given triple (subject, predicate, object) in the knowledge graph.
-
Benchmark datasets
- Freebase: Freebase86M, FB15K, FB15K237
- Wikidata
- YAGO
- WordNet: WN18, WN18RR
- DBPedia
- NELL
-
Frameworks
- DGL-KE
- LibKGE
-
Metrics
- FMR: the mean of the test triples’ ranks - corrupted triples that are already in training, test or validation sets do not participate in ranking.
- FMRR: the average inverse of the harmonic mean of the test triples’ ranks - corrupted triples that are already in training, test or validation sets do not participate in ranking.
- Hits@K: the percentage of top 𝑘 results that are correct.